Emulation is a fascinating area of software engineering, being able to bring to life a 30+ year old arcade machine on a modern computer is an incredibly satisfying accomplishment. Unfortunately I’ve become increasingly disillusioned with the lack of ambition shown by those in the emulation community. Whilst the rest of world moves onto cloud first, massively distributed architectures, emulation is still stuck firmly in the 20th century writing single threaded C++ of all things.
This project was born out of a desire to bring the best of modern design back to the the future of ancient computing history.
So what can the best of modern architecture bring to the emulation scene?
- Hot swappable code paths allowing for in game debugging
- Different languages for different components
- Secure by default (mTLS on all function calls)
- Scalability
- Fault tolerance
- Cloud native design
This culminated in the implementation of an 8080 microprocessor utilising a modern, containerised, microservices based architecture running on kubernetes with frontends for a CP/M test harness and a full implementation of the original Space Invaders arcade machine.
The full project can be found as a github organisation https://github.com/21st-century-emulation which contains ~60 individual repositories each implementing an individual microservice or providing the infrastructure. This article goes into details on the technical architecture and issues I ran into with the project.
Key starting points to learn more are:
- A react based 8080 disassembler running on github pages - https://github.com/21st-century-emulation/disassembler-8080
- The CP/M test harness used to validate the processor - https://github.com/21st-century-emulation/cpm-test-harness
- Just use
docker-compose up --buildin this repo to run the application
- Just use
- Space Invaders UI - https://github.com/21st-century-emulation/space-invaders-ui
- Run locally with
docker-compose up --buildor use the following project to deploy into kubernetes
- Run locally with
- Kubernetes Configuration & Deploying - https://github.com/21st-century-emulation/space-invaders-kubernetes-infrastructure
- Note that this presupposes that you have access to a kubernetes cluster which can handle ~200 new pods
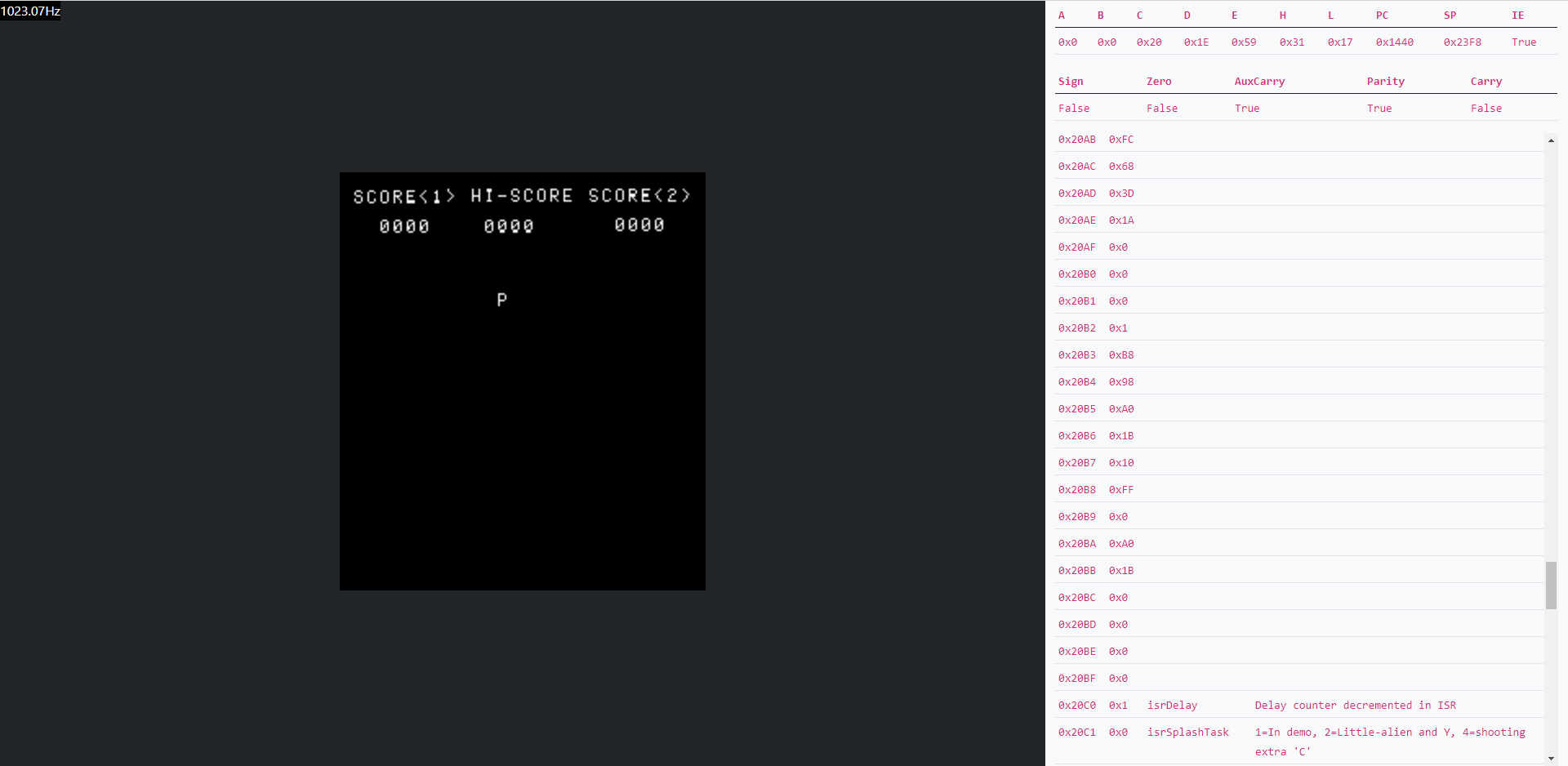
Finally, a screenshot of the emulator in action can be seen here:
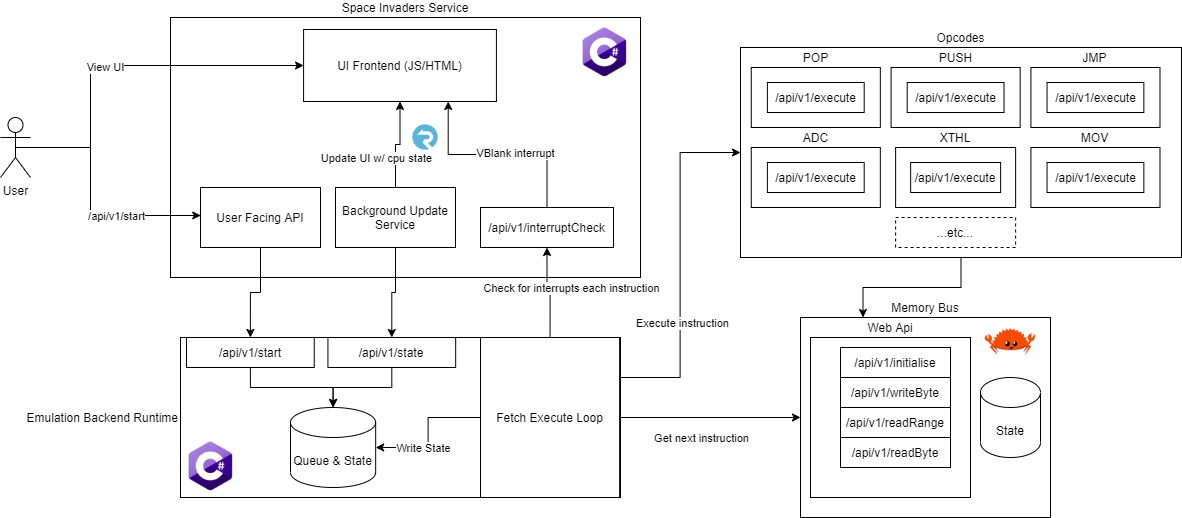
Architectural Overview
The following image describes the full archictectural model as applied to a space invaders arcade machine, the key components are then drawn out in the following sections
Central Fetch Execute Loop
All old school emulators fall into one of two camps, either they step the CPU one instruction at a time and then catch up other components or they step each component (including the CPU) one
cycle at a time. The 8080 as played in a space invaders cabinet gains nothing from being emulated with cycle level accuracy so this emulator adheres to the former design.
The Fetch Execute Loop service is the service which then performs that core loop and is broadly shaped as follows
while true:
Call microservice to check if interrupts should occur
If so then run RST x instruction
Get next instruction from memory bus microservice
Call corresponding opcode microservice
That’s it. In order to actually drive this microservice we also provide /api/v1/start and /api/v1/state endpoints which correspondingly trigger a new instance of the CPU to run and get the status of the currently running CPU.
Opcode microservices
Every opcode corresponds to a microservice which must provide a POST api at /api/v1/execute taking a JSON body shaped as follows:
{
"id": "uuid",
"opcode": 123, // Current opcode used to disambiguate calls to e.g. MOV (MOV B,C or MOV B,D)
"state": {
"a": 0,
"b": 0,
"c": 0,
"d": 0,
"e": 0,
"h": 0,
"l": 0,
"flags": {
"sign": false,
"zero": false,
"auxCarry": false,
"parity": false,
"carry": false,
},
"programCounter": 100,
"stackPointer": 1000,
"cyclesTaken": 2000,
"interruptsEnabled": false,
}
}
Memory bus
The memory bus serves to provide the stateful storage for the service and must expose 4 routes to the other services:
/api/v1/readByte?id=${cpuId}&address=${u16}- Read a single byte from the address passed in/api/v1/writeByte?id=${cpuId}&address=${u16}&value=${u8}- Write a single byte to the address passed in/api/v1/readRange?id=${cpuId}&address=${u16}&length=${u16}- Read at mostlengthbytes starting at address (to get e.g. the 3 bytes that correspond to an instruction)/api/v1/initialise?id=${cpuId}- POST takes a base64 encoded string as body and uses that to initialise the memory bus for the cpu id passed in
There’s a simple & fast implementation written in rust with a high tech in memory database provided at https://github.com/21st-century-emulation/memory-bus-8080. Alternative implementations utilising persistent storage are left as an exercise for the reader. A blockchain based backend is probably the best solution to this problem.
Interrupt service
When running the fetch execute loop service you can optionally provide (via an environment variable) the url to an interrupt check service which will be called before every opcode is executed. This API must take the same JSON body as the opcode microservices and will return an optional value which indicates which RST opcode is to be taken (or none if no interrupt is to be fired).
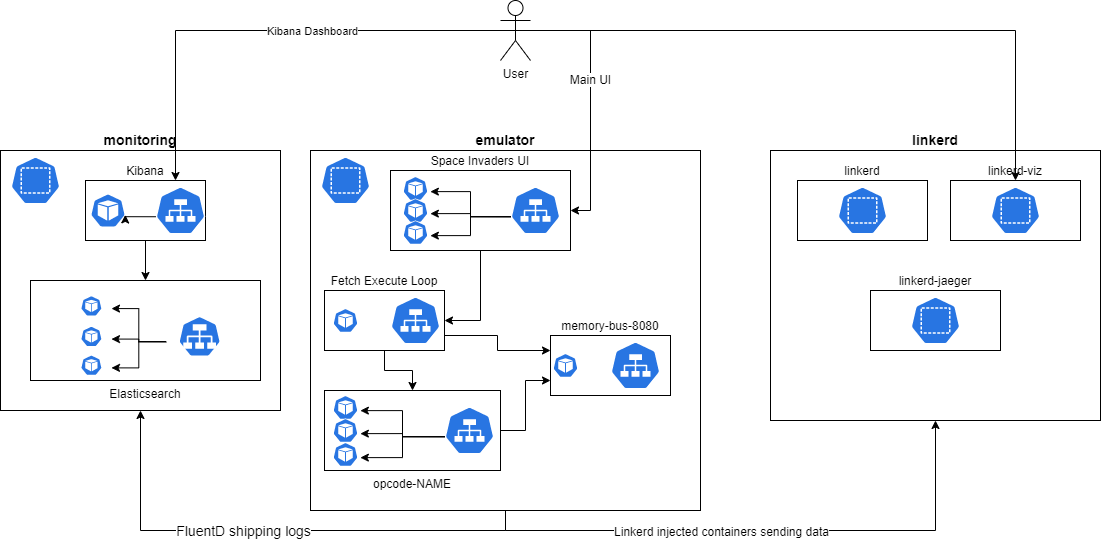
Deployment architecture
Whilst the application can be run locally using docker-compose, no self-respecting cloud solutions architect would be satisfied with the risks inherent in having everything pinned to a single machine. Consequently this project also delivers a helm chart which can be found here.
Given that repository and a suitably large kubernetes cluster (note: we strongly recommend choosing a top tier cloud provider like IBM for this), all components can be installed by simply running ./install.sh.
The kubernetes architecture is outlined in https://github.com/21st-century-emulation/space-invaders-kubernetes-infrastructure/blob/main/README.md but a diagram is provided here for brevity:
Performance
As with all modern design it’s crucial to adhere to the model of “make it work then make it fast” and that’s something that this project really takes to heart. In 1974 when the 8080 was released it achieved a staggering 2MHz. Our new modern, containerised, cloud first design doesn’t quite achieve that in it’s initial iteration. As can be seen from the screenshot above, space invaders as deployed onto an AKS cluster runs at ~1KHz which gives us ample time for debugging but does make actually playing it slightly difficult.
However, now that the application works we can look at optimising it, the following are clear future directions for it to go in:
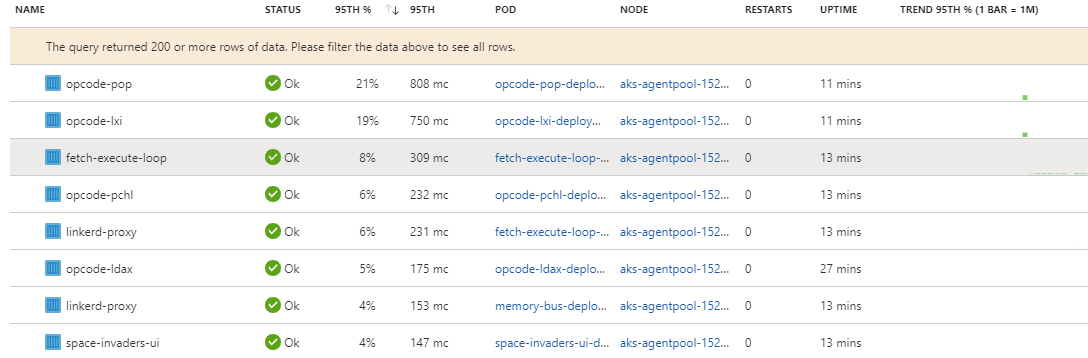
- Rewrite more things in rust. As we can see in the image below, a significant portion of the total CPU time was spent running
LXI&POPopcodes. This is quite understandable becauseLXIis written in Java/Spring andPOPis written in Scala/Play. Both are clearly orders of magnitude slower than all the other languages in play here.![Space Invaders Pod Metrics]()
- JSON -> Avro/Protobuf. JSON serialisation/deserialisation is known to be too slow for modern applications, using a better binary packed format will obviously increase performance
- Pipelining & speculative execution.
- A minor speed boost can be achieved by simply pipelining up to the next N instructions and invalidating the pipeline on any instruction which changes the program counter. This is particularly excellent because it brings modern CPU design back to the 8080!
- Since all operations internally are async and wait on IO we can trivially execute multiple instructions in parallel, a further enhancement would therefore be to speculatively execute instructions and rollback if the execution of a previous one would have affected the result.
- Memory caches
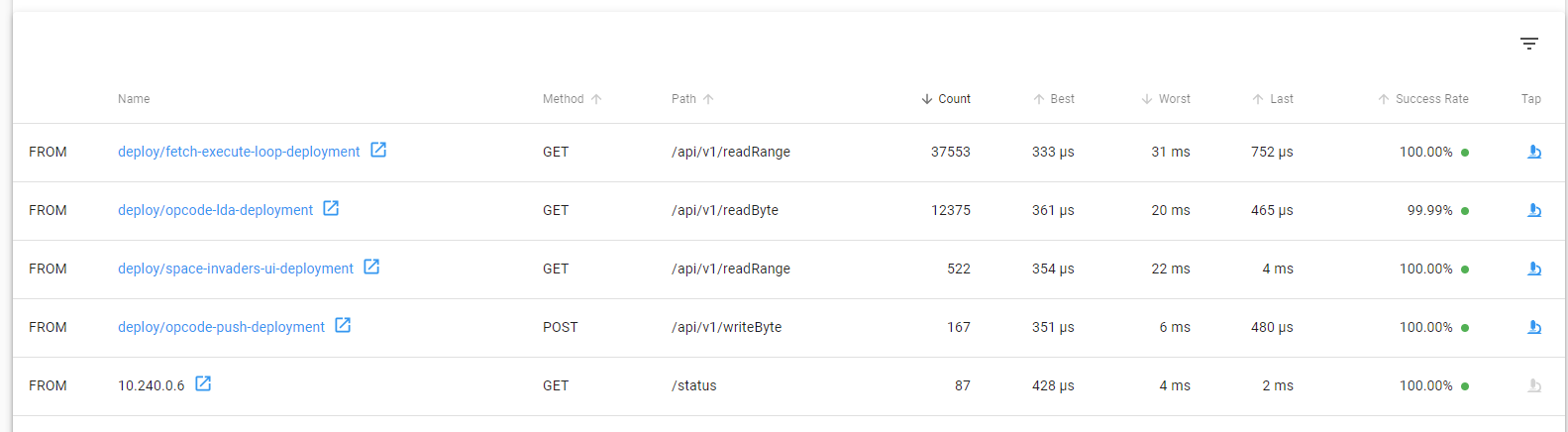
- Having to access the memory bus each time is slow, by noting which instructions can affect memory we are able to act like a modern VM and cache memory until a write happens at which point we invalidate the cache and continue. See the below image showcasing the amount of requests made to
/api/v1/readRangeform the fetch execute loop (which uses that API to get the next instruction).![Space Invaders API Calls]()
- Having to access the memory bus each time is slow, by noting which instructions can affect memory we are able to act like a modern VM and cache memory until a write happens at which point we invalidate the cache and continue. See the below image showcasing the amount of requests made to
Implementation Details
One of the many beautiful things about a microservice architecture is that, because function calls are now HTTP over TCP, we’re no longer limited to a single language in our environment. That allows us to really leverage the best that modern http api design has to offer.
The following table outlines the language choice for each opcode, as you can see, this allows to gain the benefits of Rusts safe integer arithmetic operations whilst falling back to the security of Deno for important operations like CALL & RET.
| Opcode | Language | Description | Runtime image size | Performance (avg latency) |
|---|---|---|---|---|
| MOV | Swift | Moves data from one register to another | 257MB | 4.68ms |
| MVI | Javascript | Puts 8 bits into register, or memory | 118MB | 3.43ms |
| LDA | VB | Puts 8 bits at location Addr into A Register | 206MB | 4.56ms |
| STA | C# | Stores 8 bits at location Addr | 206MB | 4.61ms |
| LDAX | Typescript | Loads A register with 8 bits from location in BC or DE | 365MB | 6.22ms |
| STAX | Python | Stores A register at location in BC or DE | 59MB | 5.24ms |
| LHLD | Ruby | Loads HL register with 16 bits found at Addr and Addr+1 | 898MB! | 13.63ms |
| SHLD | Perl | Stores HL register contents at Addr and Addr+1 | 930MB! | 12.68ms |
| LXI | Java + Spring | Loads 16 bits into B,D,H, or SP | 415MB | 6.84ms |
| PUSH | Lua | Puts 16 bits of BP onto stack SP=SP-2 | 385MB | 4.42ms |
| POP | Scala + Play | Takes top of stack, puts it in RP SP=SP+2 | 761MB | 13.99ms |
| XTHL | D | Exchanges HL with top of stack | 156MB | 26.54ms |
| SPHL | F# | Puts contents of HL into SP (stack pointer) | 114MB | 3.25ms |
| PCHL | Kotlin | Puts contents of HL into PC (program counter) [=JMP (HL)] | 445MB | 7.61ms |
| XCHG | C++ | Exchanges HL and DE | 514MB | 2.16ms |
| ADD | Rust | Add accumulator and register/(HL) | 123MB | 1.95ms |
| ADC | Rust | Add accumulator and register/(HL) (with carry) | 123MB | 2.00ms |
| ADI | Rust | Add accumulator and immediate | 123MB | 2.16ms |
| ACI | Rust | Add accumulator and immediate (with carry) | 123MB | 2.22ms |
| SUB | Rust | Sub accumulator and register/(HL) | 123MB | 1.95ms |
| SBB | Rust | Sub accumulator and register/(HL) (with borrow) | 123MB | 1.70ms |
| SUI | Rust | Sub accumulator and immediate | 123MB | 2.15ms |
| SBI | Rust | Sub accumulator and immediate (with carry) | 123MB | 1.91ms |
| ANA | Rust | And accumulator and register/(HL) | 123MB | 2.68ms |
| ANI | Rust | And accumulator and immediate | 123MB | 1.93ms |
| XRA | Rust | Xor accumulator and register/(HL) | 123MB | 1.70ms |
| XRI | Rust | Xor accumulator and immediate | 123MB | 1.57ms |
| ORA | Or accumulator and register/(HL) | 74MB | 11.36ms | |
| ORI | Rust | Or accumulator and immediate | 123MB | 1.40ms |
| DAA | Rust | Decimal adjust accumulator | 123MB | 2.26ms |
| CMP | Rust | Compare accumulator and register/(HL) | 123MB | 1.70ms |
| CPI | Rust | Compare accumulator and immediate | 123MB | 1.90ms |
| DAD | PHP | Adds contents of register RP to contents of HL register | 430MB | 17.2 ms |
| INR | Crystal | Increments register | 23MB | 1.98ms |
| DCR | Crystal | Decrements register | 23MB | 2.06ms |
| INX | Crystal | Increments register pair | 23MB | 2.01ms |
| DCX | Crystal | Decrements register pair | 23MB | 1.99ms |
| JMP | Powershell | Unconditional Jump to location Addr | 294MB | 6.51ms |
| CALL | Deno | Unconditional Subroutine call to location Addr | 154MB | 6.04ms |
| RET | Deno | Unconditional return from subroutine | 154MB | 6.43ms |
| RLC | Go | Rotate left carry | 6MB | 2.28ms |
| RRC | Go | Rotate right carry | 6MB | 2.19ms |
| RAL | Go | Rotate left accumulator | 6MB | 2.39ms |
| RAR | Go | Rotate right accumulator | 6MB | 2.29ms |
| IN | Data from Port placed in A register | |||
| OUT | Data from A register placed in Port | |||
| CMC | Haskell | Complement Carry Flag | 90MB | 2.50ms |
| CMA | Haskell | Complement A register | 90MB | 2.54ms |
| STC | Haskell | Set Carry Flag = 1 | 90MB | 2.52ms |
| HLT | Halt CPU and wait for interrupt | |||
| NOOP | C | No operation | 70MB | 1.89ms |
| DI | Dart | Disable Interrupts | 79MB | 2.37ms |
| EI | Dart | Enable Interrupts | 79MB | 2.21ms |
| RST | Deno | Call interrupt vector | 154MB | 7.34ms |
Nim was a bit late to the party so only got one opcode, and it still managed to be slow anyway.
Code details
According to SCC this project cost $1M to make, which is probably several orders of magnitude less than Google will pay for it. Like any true modern application it also consists of significantly more JSON/YAML than code.
───────────────────────────────────────────────────────────────────────────────
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
YAML 144 6873 859 396 5618 0
Dockerfile 112 2007 505 353 1149 248
JSON 106 15383 240 0 15143 0
Shell 64 2448 369 195 1884 257
Plain Text 59 404 171 0 233 0
Docker ignore 56 295 0 0 295 0
Markdown 56 545 165 0 380 0
gitignore 56 847 129 178 540 0
C# 35 1803 198 10 1595 51
TypeScript 22 1335 116 30 1189 275
Rust 18 1825 241 7 1577 79
TOML 18 245 20 0 225 0
Java 7 306 66 0 240 1
Haskell 6 207 24 0 183 0
Visual Basic 6 119 24 0 95 0
MSBuild 5 53 13 0 40 0
Crystal 4 330 68 4 258 5
Go 4 255 33 0 222 6
JavaScript 4 147 8 1 138 5
License 4 84 16 0 68 0
PHP 4 147 21 43 83 2
Swift 4 283 15 4 264 1
C++ 3 32 4 0 28 0
Emacs Lisp 3 12 0 0 12 0
Scala 3 112 15 0 97 6
XML 3 97 13 1 83 0
C Header 2 24 2 0 22 0
CSS 2 44 6 0 38 0
Dart 2 58 6 0 52 18
HTML 2 361 1 0 360 0
Lua 2 65 8 0 57 15
Properties File 2 2 1 0 1 0
C 1 63 8 0 55 18
CMake 1 68 10 15 43 4
D 1 71 6 2 63 14
F# 1 88 11 3 74 0
Gemfile 1 9 4 0 5 0
Gradle 1 32 4 0 28 0
Kotlin 1 40 9 0 31 0
Makefile 1 16 4 0 12 0
Nim 1 82 9 0 73 2
Perl 1 49 6 3 40 4
Powershell 1 78 9 0 69 10
Python 1 37 6 0 31 1
Ruby 1 28 6 0 22 0
SVG 1 3 0 0 3 0
TypeScript Typings 1 1 0 1 0 0
───────────────────────────────────────────────────────────────────────────────
Total 833 37413 3449 1246 32718 1022
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $1,052,256
Estimated Schedule Effort (organic) 14.022330 months
Estimated People Required (organic) 6.666796
───────────────────────────────────────────────────────────────────────────────
Processed 1473797 bytes, 1.474 megabytes (SI)
───────────────────────────────────────────────────────────────────────────────
Issues
Naturally I ran into a number of new issues with this approach. I’ve listed some of those below to give a flavour for the types of problems with this architecture:
- Github actions…
- Random timeouts logging in to ghcr.io, random timeouts pushing images. Generally just spontaneous errors of all sorts. This really drove home how fun it is managing the development toolchain for a microservice architecture
- Haskell compiler images
- Oh boy. Haskell won the award for my least favourite development environment solely off the back of the absurd 3.5GB SDK image! That was sufficiently large that it was impossible to build the haskell based services in CI without fine tuning the image down to < 3.4GB (github actions limits)
- Intermittent AKS networking errors
- Whilst it achieved ~4 9s availability across all microservices, there were spontaneous 504s between microservices in the AKS implementation.
- On the plus side, because we’re using linkerd as a service mesh to give us secure microservice TCP connections we can also just leverage it’s retry behavior and forget about the problem! Exactly like a modern architecture!
- DNS caching (or not)
- Only node.js of all the languages used had issues where it would hammer the DNS server on literally every HTTP request, eventually DNS told it to piss off and the next request broke #justnodethings
- Logging at scale
- I initially set up Loki as the logging backend because it’s new and therefore good, but found that the C# libraries for Loki would occasionally send requests out of order and that in the end Loki would just give up and stop accepting logs - fortunately fluentd is still very much in the spirit of this project and really pins the project down to kubernetes so it was obviously the best decision all along
- Orchestrating changes across services
- Strangely, having ~50 repositories to manage was marginally harder than having 1. Making a change to (for example) add an
interruptsEnabledflag to the CPU needed to be orchestrated across all microservices. Fortunately I’m quite good at writing disgusting bash scripts like any self respecting devops engineer.
- Strangely, having ~50 repositories to manage was marginally harder than having 1. Making a change to (for example) add an
Is this actually possible?
Alright, if you’ve got this far I’m sure you’ve realised that the whole project is something of a joke. That said it is also an interesting intellectual exercise to consider whether it’s remotely possible to achieve >=2MHz with the architecture delivered.
The starting point is that to achieve 2MHz we must deliver 1 instruction every 2μs
2MHz = 2,000,000 cycles per second
Each instruction is at 4-17 cycles so we need to manage at worst 2,000,000 / 4 = 500,000 instructions per second. That gives 1/500,000 seconds = ~2μs per operation.
As it was written there are 3 HTTP calls per instruction, one to fetch the operation, one to execute it and one to check for interrupts.
Assuming for sake of argument that we do the following optimisations:
- Make interrupt checks off the hot path
- Cache all ROM in the fetch execute service and assume applications only execute from ROM (true for space invaders)
- This takes us to ~1 instruction per operation
- Change from JSON w/ UTF8 encoding to sending a byte packed array of values to represent the CPU
- Drives the request size down to <256 bytes and eliminates all serialization/deserialization costs (just have a struct pointer pointing at the array)
Then we can get to a good starting point of exactly 1 round trip to/from each opcode. So what’s the minimal cost for a roundtrip across network?
This answer (https://quant.stackexchange.com/questions/17620/what-is-the-current-lowest-possible-latency-for-tcp-communication) from 2015 benchmarks loopback device latency at ~2μs if the request size can be kept down to <=256 bytes.
Assuming that person knows what they’re talking about then the immediate answer is a straight no. You’ll never achieve the required latency across a network (particularly a dodgy cloud data center network).
But let’s not give up quite yet. We’re not miles away from the performance required so we can look for 2 times speed ups.
Some thoughts on methods to get that last 2 times speed up:
- Fire and forget memory writes
- A memory write is almost never read immediately, so just chuck it at the bus and don’t bother blocking until it’s written. Maybe you’ll lose some writes? That’s fine. Very mongo. fsync is for boring c coders and modern developers aren’t supposed to need to know about nasty complex things like the CAP theorem anyway. Presumably kubernetes will solve that for us.
- We can execute multiple operations in parallel and only validate the correctness of their results later.
- This would clearly speed up operations like memset’s which are done with simple
MVI (HL) d8->DCX HL->JNZtype algorithms where each grouping can be executed in parallel
- This would clearly speed up operations like memset’s which are done with simple
- If each opcode was capable of knowing the next instruction then we could avoid the second half of each round trip and not travel back to the fetch execute loop until the stream of instructions has run out
- This is basically a guaranteed 2 times speed up
Conclusion? I think it might be possible under some ideal situations assuming ~no network latency but I’ve no intention of spending any more time thinking about it!